
监督微调(SFT)基本上是当今锻练大模子时必走的路。不论你要让模子干什么,先用 SFT 让它学会基本的指示随从和对话智商尊龙凯时体育,然后再通过 PPO 或者 GRPO 这些强化学习步地进一活动优。
但 SFT 有个老间隙:容易过拟合。模子会死记硬背锻练数据,泛化智商变差。更要命的是,经过 SFT 锻练的模子在后续的强化学习阶段常常探索智商不及,这即是所谓的"熵崩塌"表象 - 模子变得过于慑服,生成的内容单调乏味。
这篇论文建议了 Proximal Supervised Fine-Tuning (PSFT),骨子上是把 PPO 的念念路引入到 SFT 中。这个意见挺奥秘的:既然 PPO 或者巩固政策更新,那为什么不必访佛的机制来巩固监督学习的参数更新呢?
先说说传统的监督微调如何回事。SFT 即是拿一堆(教导,恢复)这么的数据对,让模子学会从教导生成对应的恢复。

最小化模子量度的 token 漫步和真确 token 之间的交叉熵亏损。但问题在于,要是锻练数据和预锻练数据的漫步各异相比大,每一步的参数更新可能都很激进,导致模子健忘之前学到的通用智商。


PPO vs. GRPO
这种激进更新还会激发熵崩塌。简便说即是模子在聘任下一个 token 时变得过于自信,险些莫得不慑服性。这么一来,模子生成的内容就会变得终点可量度,枯竭万般性。更糟的是这种低熵情状会让模子在后续的强化学习锻练中失去探索新政策的智商。
从强化学习的角度看谈话建模要纠合 PSFT,得先把谈话生成过程纠合成一个马尔可夫有野心过程(MDP)。这听起来很概述,但其实挺直不雅的:

在谈话生成的 MDP 中,情状空间包含智能体可能处于的通盘可能情状,看成空间包含智能体不错继承的通盘可能看成或迁移,迁移概率 P(s'|s, a) 默示当智能体继承看成 a 时,从情状 s 迁移到 s' 的可能性。
具体到谈话模子:情状 s(t) 即是刻下的蜿蜒文(输入 query 加上仍是生成的通盘 token),看成 a(t) 即是要生成的下一个 token,迁移概率是慑服性的(等于1),因为采取 token 后新情状就慑服了。
大谈话模子的输出漫步 π(θ) 即是咱们的政策。关于输入 x,模子生成输出 y 的融合概率是:
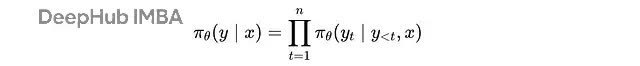
给定查询 'x' 生成输出 'y' 的融合概率是在每个时代步 't' 给定其前置蜿蜒文 (y(
SFT 的亏损函数即是圭臬的交叉熵:
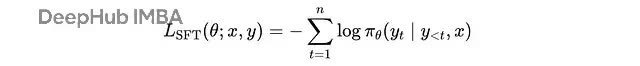
每个教导-完成对 (x, y) 的 SFT 亏损
这里 y(t) 是时代步 t 的生成令牌,n 是生成令牌的总额,y(
对通盘这个词锻练集,SFT 亏损不错写成:
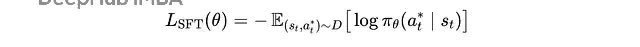
锻练技能使用梯度下跌最小化的 SFT 亏损
这里 s(t) 是时代步 t 的蜿蜒文,a(t) 默示正确的下一个令牌。
SFT 其实是政策梯度的特例强化学习里有三大类算法:基于价值的步地(比如 Q-learning)、政策梯度步地(比如 REINFORCE)、还有羼杂步地(比如 Actor-Critic)。
政策梯度步地的野心函数是:
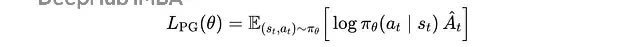
强化学习锻练技能使用梯度高潮最大化的政策梯度野心
这里 s(t), a(t) 是从刻下政策采样的情状-看成对,log π(θ)(a(t)|s(t)) 是政策继承看成的对数概率,Â(t) 是上风函数,告诉咱们这个看成比平均水平好若干。

上风函数是在特定情状下继承看成的 Q 函数与给定情状的价值函数之间的差值。
要是 Â(t) > 0,说明这个看成比预期好,锻练会增多它的概率。
仔细望望,SFT 其实即是政策梯度的简化版块:
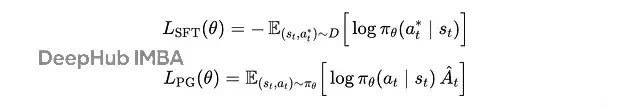
SFT 亏损 vs. 政策梯度野心
分别在于:SFT 不是从政策采样轨迹,而是从固定数据集采样;SFT 把上风函数固定为 1,也即是假定数据集里的看成都是"好的"。
从 REINFORCE 到 PPO传统的政策梯度步地比如 REINFORCE 有个问题:要是某一步更新太大,新政策可能偏离旧政策太远,导致锻练不巩固。
TRPO(信任区域政策优化)通过引入 KL 散度经管来处罚这个问题:

TRPO 的代理野心(保守政策迭代)野心,在强化学习锻练技能使用梯度高潮最大化,其中 r(t)(θ) 是病笃性采样比率。
这里用病笃性采样来修正新旧政策之间的各异,同期用 KL 散度经管来阻挡更新幅度:
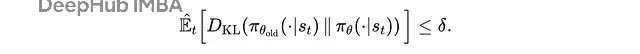
在 TRPO 中,代理野心在使用新政策 π(θ) 和旧政策 π(θ)(old) 之间的 KL 散度对政策更新大小的经管下最大化。
但 TRPO 计较量太大,不太实用。PPO 就简便多了,告成在野心函数里加个 clipping:
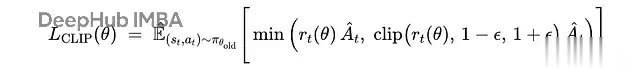
PPO 中最大化的编著代理野心,其中 r(t)(θ) 是病笃性采样比率,ϵ 时时是一个小值(举例,0.2)。在 TRPO 和 PPO 中,上风 Â(t) 的近似值使用广义上风算计(GAE)计较。
近端政策优化
PPO 通过编著病笃性采样比率来防护政策更新过大,既简便又灵验。
PSFT:给 SFT 加上 PPO 的巩固性既然知说念了 SFT 是政策梯度的特例,那咱们能弗成给它也加上 PPO 的巩固性机制?谜底即是 PSFT。
PSFT 的野心函数是:
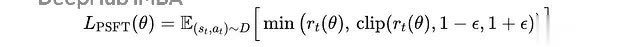
近似监督微调(PSFT)野心
张开病笃性采样比率:

张开的近似监督微调(PSFT)野心
这个假想很奥秘:通过相比新旧政策的概率比值并进行编著,PSFT 或者防护模子参数更新过于激进。这么既能学习新任务,又能保抓原有的通用智商,同期幸免熵崩塌。
实践恶果如何样谋略者在 Qwen2.5-7B-Instruct 和 Llama3.1-8B-Instruct 上作念了实践,主要看数学推明智商的提高。
领先是熵的变化。PSFT 或者看守更平滑的熵弧线,幸免了传统 SFT 中的熵崩塌表象:
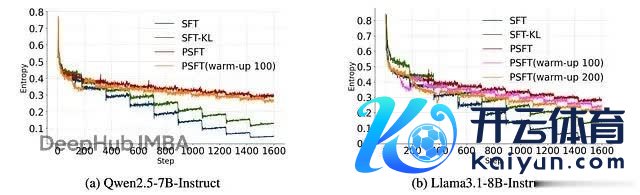
流露两个大谈话模子在锻练技能熵的图。SFT-KL 是一种利用 KL 刑事职守以保抓微调模子更接近预锻练模子漫步的步地。PSFT (warm-up) 是一种在切换到 PSFT 之前入手移时的运行 SFT 阶段的步地,用于锻练巩固性。
在域内数学任务上,PSFT 的发扬至少和圭臬 SFT 抓平,在某些情况下还更好:
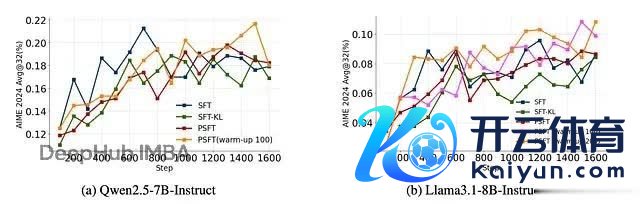
流露域内性能锻练动态的图
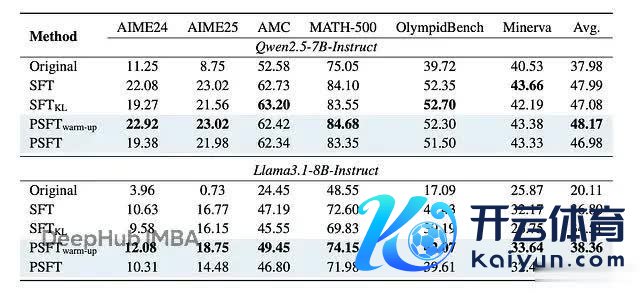
域内性能的终结,其中关于 >AIME 和 AMC 基准,终结是 avg@32。关于其余的,终结是 avg@8。
更病笃的是域外性能。PSFT 锻练的模子在非数学任务上也发扬很好,说明它如实提高了泛化智商:
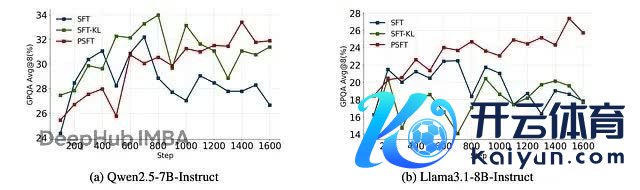
流露域外性能锻练动态的图
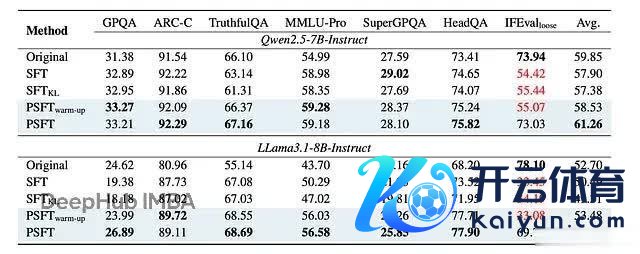
域外性能的终结。关于 GPQA、ARC-C、TruthfulQA 和 IFEval,终结是 avg@8。关于其余的,终结是 pass@1。
在后续的强化学习锻练中,PSFT 锻练的模子保抓了更高的熵,说明探索智商取得了保留:

流露强化学习实践中域内性能锻练动态的图
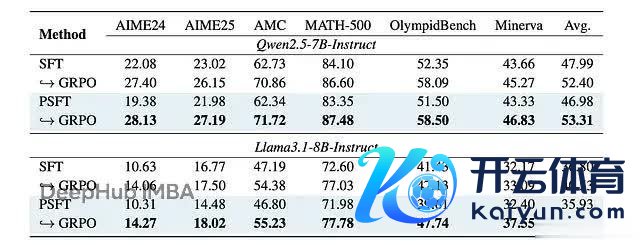
强化学习实践中域内性能的终结
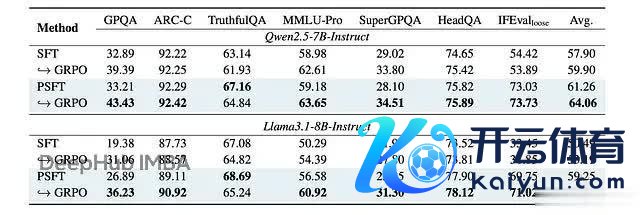
强化学习实践中域外性能的终结
PSFT 的上风不单体当今数学推理上,在模子对都方面也有匡助。用 DPO 进行对都锻练时,PSFT 预锻练的模子发扬更巩固:
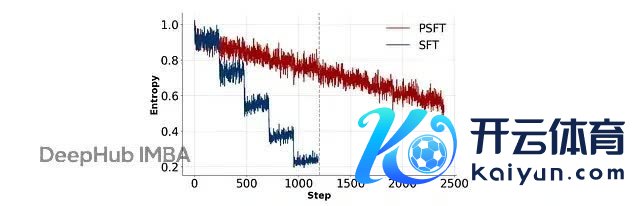
流露 SFT/PSFT 后跟 DPO 的对都锻练技能熵演变的图
在万般对都基准上,PSFT 都比传统 SFT 发扬更好:
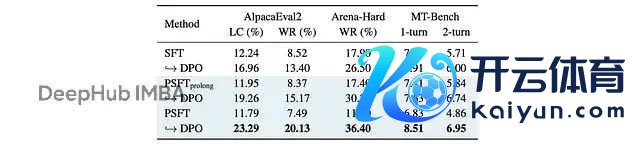
在不同对都基准上对 Qwen3–4B-Base 进行 DPO 锻练的终结。PSFT(prolong) 是 PSFT 的推广版块,接续锻练更多要领。
追忆PSFT 骨子上是把强化学习中巩固政策更新的念念想引入到监督学习中。通过模仿 PPO 的编著机制,PSFT 或者:
防护模子参数更新过于激进
保抓模子的通用智商和探索性
幸免熵崩塌表象
为后续的强化学习锻练打下更好的基础
这个责任挺特意旨真理的,它展示了监督学习和强化学习之间深层的相关。更病笃的是尊龙凯时体育,它提供了一个简便灵验的步地来改善现存的锻练进程。要是你正在作念大模子的锻练责任,PSFT 总计值得试试。